How to A/B test a conversational AI agent
Why guessing is the expensive option
A conversational agent is not one thing you tune. It is a stack of decisions: how it greets a shopper, how warm or terse it sounds, when it offers help, how it recommends products, and how it walks someone through returns or sizing. Each of those is a knob — and with language, small changes move money.
“Want me to narrow it down?” lands differently from “Here are three options.” You cannot reason your way to the right wording, because shopper behaviour rarely matches your intuition. The alternative to testing — edit the prompt, eyeball last week’s numbers, declare victory — is guessing with extra steps. Traffic shifts, a promo runs, and you have no idea whether your change helped, hurt, or did nothing.
In WisWes, A/B testing is an Enterprise feature. It runs two or more variants of the assistant’s prompts or conversation flows at the same time, so the comparison happens under identical conditions instead of week-over-week.
What you can actually test
The useful tests live at the level of behaviour the shopper feels:
- Greeting and persona. Opening line, tone, how proactive the first message is. Concise-and-direct versus warm-and-guiding is a classic first test.
- How it recommends. One hero pick versus three options. Leading with price versus leading with fit. Asking a clarifying question before recommending versus recommending immediately.
- Conversation flows. A guided “help me choose” flow with structured steps versus free-form back-and-forth; a streamlined returns flow versus a generic one.
- Proactive offer wording. When the agent steps in to keep a shopper from leaving, the exact phrasing and offer is highly testable.
Start with the surfaces most shoppers hit: the greeting and the recommendation style touch nearly every session, so a win there compounds.
How to run a clean test
Four rules separate a test you can trust from theatre.
1. Change one thing at a time. If Variant B has a new greeting and a new recommendation style, a win tells you nothing about which change did the work. One variable per test.
2. Assign randomly, and keep the session sticky. Each new shopper should be randomly dropped into a variant, then kept on it for the whole session — WisWes does this for you. Stickiness matters more for a conversational agent than for a static page: a chat is a continuous relationship. If a shopper got a warm, guiding persona in message one and a clipped one in message four, the experience breaks and the data is noise.
3. Get enough traffic. A handful of conversations cannot tell you anything. Lower-traffic stores should run tests longer rather than calling them in a day.
4. Pick one primary metric before you start. Decide what “winning” means up front. If you wait until the data is in and then go shopping for a metric where B looks good, you will always find one — and it will mean nothing.
What to measure
WisWes tracks three things per variant: conversations, win-backs, and completed checkouts. Choose your primary metric from the bottom of that list, not the top.
| Metric | What it tells you | Primary? |
|---|---|---|
| Conversations | How many shoppers engaged the variant | No — it’s the denominator, not a result |
| Win-backs | Shoppers pulled back from leaving and converted | Yes, if the test targets the proactive layer |
| Completed checkouts | Sessions that ended in a purchase | Yes — the default primary metric |
Message count, session length, and “deflection” are vanity traps. A variant that drives more completed checkouts made the store money. That is unambiguous.
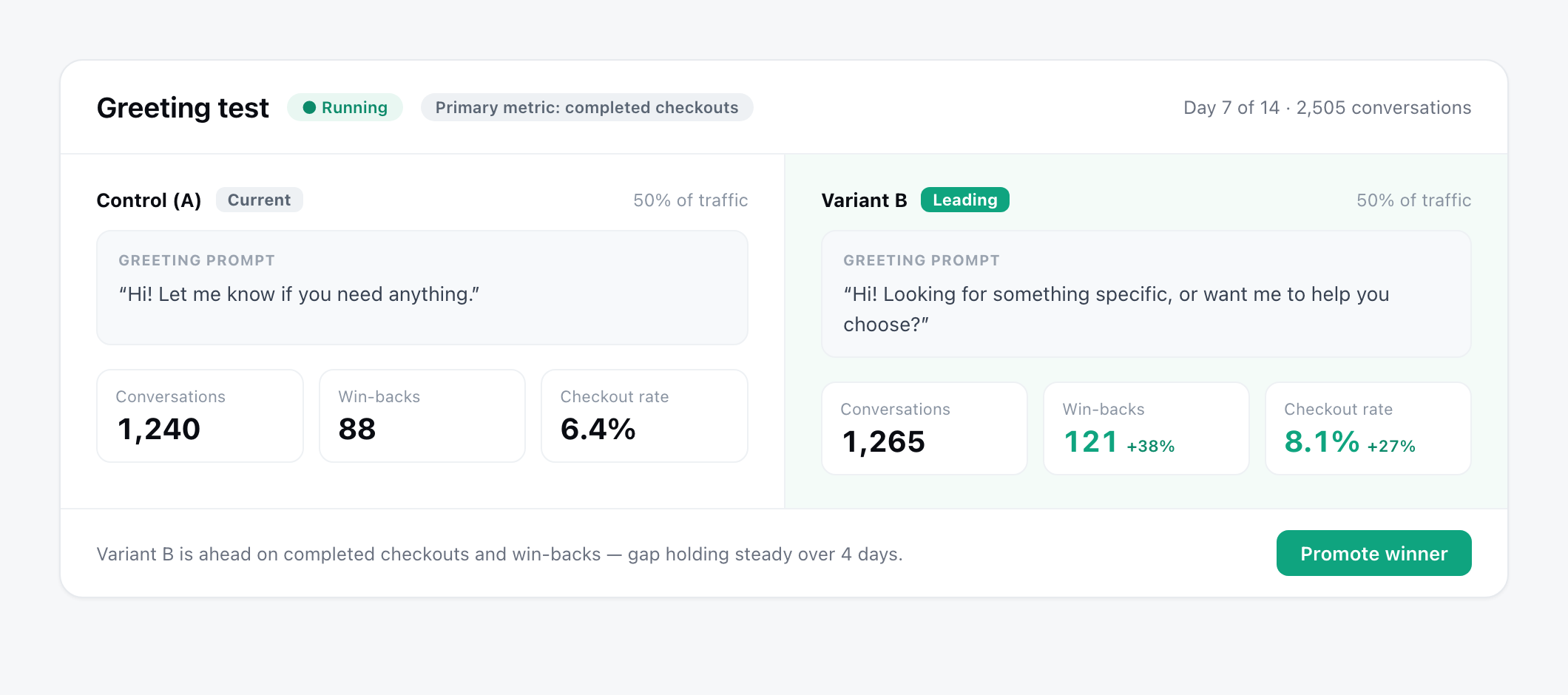
Reading results and calling a winner
The single most common mistake is stopping too early. Run a test for a day, see Variant B ahead, ship it — and next week it underperforms, because the early lead was noise. Hold the line:
- Wait for enough sessions per variant. A 3-checkout lead on 40 conversations is a coin flip, not a result.
- Look for a clear, stable gap. If the variants trade places day to day, you do not have a winner yet. A real winner pulls ahead and stays ahead.
- Beware tiny samples on win-backs. Win-backs are rarer than checkouts, so they need more time to accumulate a trustworthy gap.
When one variant is clearly and consistently ahead on your primary metric, promote it in the dashboard. It becomes the new control, and your next test challenges it.
A worked example
Say you want to test how the agent opens a conversation.
- Control (A): “Hi! Let me know if you need anything.” Passive — waits for the shopper.
- Variant (B): “Hi! Looking for something specific, or want me to help you choose?” Active — offers a guided path immediately.
You change only the greeting; everything downstream stays identical. Primary metric: completed checkouts. A week in, Variant B is consistently ahead and the gap is holding steady across days, not bouncing. That is a winner — you promote B, and B becomes your new control.
Now the next question writes itself: does the guided opener work even better as a full “help me choose” flow with structured steps? You have your next test, and a control worth beating. Test one knob, measure revenue, promote the winner, repeat — and over a quarter, a string of small honest wins compounds into an agent that is measurably better at selling. You can model the cost side of all this usage with the AI agent cost calculator.