Catching AI-Generated Fake Reviews — With a Model Small Enough to Ship Inside a Plugin

Fake reviews are old. What changed is who writes them. For years a fake review was a human paid a dollar to type two sloppy sentences — bad grammar, obvious tells, easy enough to spot. Now a language model writes them: fluent, specific, on-brand, and generated by the thousand. The new review-spam problem is not that the spam reads badly. It is that the spam reads perfectly.
Why this is a business problem, not a vanity metric
Reviews are the closest thing an online store has to a salesperson on the floor. Most shoppers read them before they buy, and the star rating is often the single biggest nudge between "add to cart" and "close the tab." That is exactly why fake reviews are not a cosmetic nuisance — they corrupt the one signal customers trust most. And AI changed the scale of the attack: writing a thousand believable reviews used to take a thousand people; now it takes one prompt and an afternoon.
It cuts in two directions. Fake five-stars inflate your own products — and fake one-stars, just as cheap to generate, can be aimed at your bestsellers or sprayed across a competitor's catalog. Either way, the cost lands on the business:
| Where it hurts | What it costs you |
|---|---|
| Shopper trust | A wall of suspiciously perfect reviews reads as fake — and once buyers distrust the reviews, they distrust the store. |
| Returns & refunds | Inflated ratings pull in the wrong buyers; the product underdelivers, and you eat the returns, refunds, chargebacks, and support tickets. |
| Wasted ad spend | You pay to send traffic to a listing whose social proof is fabricated; the extra bounces quietly burn the budget. |
| Marketplace penalties | Google, Amazon, and app stores down-rank or delist sellers caught hosting fake reviews. |
| Legal exposure | The FTC's 2024 rule bans fake and AI-generated reviews outright, with civil penalties that can reach tens of thousands of dollars per violation. |
| Lost compounding | Honest reviews are an asset that compounds over years; fake ones poison the well and make every genuine review look doubtful. |
So the goal is not "delete the bad reviews." It is to restore the signal — to tell a real customer's voice from a machine-written one, the moment a review lands, so a human can decide what to do about it. That is the problem the rest of this series sets out to solve.
So we set out to catch it — and the first instinct, in 2026, is to reach for a big model: feed every review to an LLM and ask "is this fake?" That works, and it is also the wrong tool. It is slow, it costs a token bill on every review, it needs an API key and a network round-trip, and it cannot tell you why in a way you can audit. You cannot ship that inside a store plugin that has to score a review grid in a single page load.
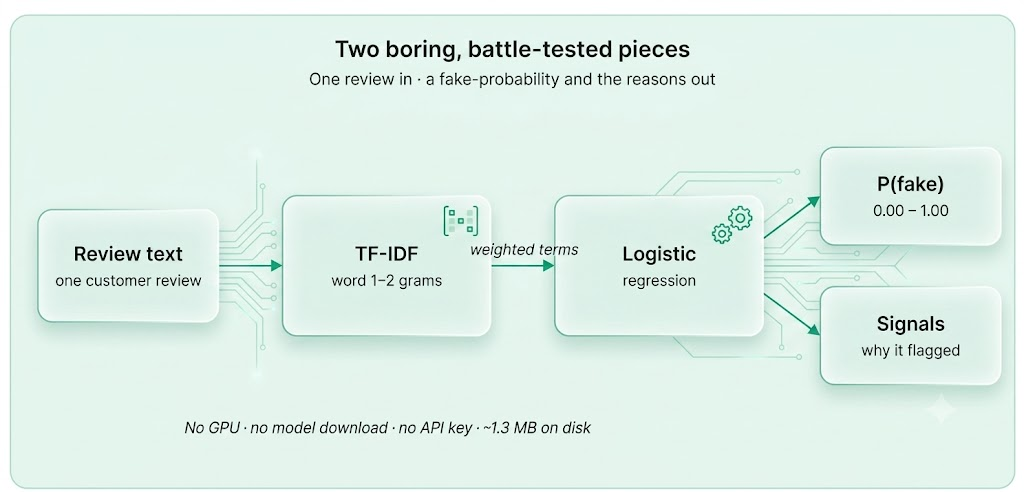
This is Part 1 of a build-in-public series. The goal for the whole series is a fake-review detector that runs inside a Magento or Shopify store — per review, instantly, offline. That constraint decides everything about the model, so we started there: a tiny, explainable classifier. It is open, it is ~1.3 MB, and it hits 94.6% accuracy on reviews it has never seen.
What "fake" means here (precisely)
We trained on the Salminen et al. Fake Reviews Dataset — about 40,000 Amazon-style reviews, each labelled one of two ways:
| Label | Meaning | We call it |
|---|---|---|
| CG | Computer-generated — a language model wrote the review | fake |
| OR | Original — a real customer wrote it | real |
So this detects machine-written reviews — exactly the modern bot-farm problem. Be clear about what it is not: it is not a sentiment detector, and it is not an "honest vs. dishonest human" judge. A real, glowing, human-written five-star review is not what it flags. It flags text that a machine produced.
Why a tiny model beats reaching for an LLM
For this job, the small classic model is not a compromise — it is the better engineering choice on every axis that matters to a plugin:
| LLM per review | This classifier | |
|---|---|---|
| Cost per review | A token bill, every time | $0 after training |
| Latency | A network round-trip | Sub-millisecond, local |
| Runs offline | No — needs an API | Yes — ~1.3 MB on disk |
| Explainable | A paragraph you must trust | The exact tokens, scored |
| Deterministic | Varies run to run | Same input, same output |
The explainability row is the one we care about most. When you flag a merchant's review, you owe them a reason — and "a large model said so" is not one. This model can hand you the precise words that moved the verdict.
The recipe
Nothing exotic. The whole pipeline is two scikit-learn components, and it trains on ~40k reviews in a few seconds on a laptop:
| Stage | What it does | Settings that matter |
|---|---|---|
| TF-IDF | Turns text into weighted word + word-pair counts | word 1–2 grams · sublinear_tf · min_df 2 · 30,000 features |
| Logistic regression | Scores those features into a fake-probability | C = 4.0 · class_weight balanced |
Two details do the heavy lifting. Bigrams (word pairs like highly recommend or love it) catch the canned, scaffolded phrasing generated reviews lean on — single words miss it. And sublinear_tf dampens repetition, so a review that says "love" five times does not get five times the weight.
The results
Trained on 32,345 reviews, tested on a held-out 8,087 it never saw:
| Metric | Score | Plain meaning |
|---|---|---|
| Accuracy | 0.946 | Of all reviews, the share it labelled correctly |
| F1 | 0.945 | Balance of catching fakes vs. false alarms |
| ROC-AUC | 0.988 | How well it ranks fake above real |
The part that makes it shippable: it shows its work
A probability alone is a black box. The reason this model earns a place in a merchant-facing tool is that it can point at the evidence. For each review it returns signals — the individual tokens whose weight (TF-IDF value × model coefficient) pushed the score toward fake.
Feed it a textbook generated review and you get back:
Input: "Love this! Well made and very comfortable. I love it!"
{
"label": "fake",
"fake_probability": 0.94,
"signals": [
{ "token": "love it", "weight": 0.71 },
{ "token": "i love", "weight": 0.40 }
]
}Try it in two commands
The whole project is open source (MIT) on GitHub — github.com/wiswes/fakereviews. It is genuinely clone-and-run: the trained model is committed, so you can predict immediately, or retrain from scratch in seconds:
pip install -r requirements.txt
# Score a review straight away (model ships in the repo)
python -m fakereviews.cli predict "Best product ever!!! Buy it now!!!"
# …or retrain from scratch — fetches the dataset, trains in seconds
python -m fakereviews.trainOr use it as a library — one import, one call, with a threshold you raise in production to flag only high-confidence fakes:
from fakereviews import FakeReviewClassifier
clf = FakeReviewClassifier()
result = clf.predict(review_text, threshold=0.5)
print(result.label, result.fake_probability)Honest limits
- It is trained on one dataset of one era of generated text. As models change, the tells change — it will need retraining on fresh fakes.
- It judges the text, not the account. A determined spammer who hand-edits machine output can soften the signal — which is why, in a real store, this is one input among several, not the whole verdict.
- A high-confidence flag is a prompt to review, not an automatic delete. The threshold is yours to set.
What's next
The model was the easy, contained part. The series gets interesting when it leaves the notebook:
- Part 2 — Magento extension (building now, open on GitHub at wiswes/fakereviews_magento): a new column in the admin reviews grid that flags machine-written reviews and shows the why, scoring each review right inside the store with no external service.
- Part 3 — Shopify app (planned): the same, for Shopify merchants.
The whole point of a 1.3 MB, no-dependency model is that it can run anywhere a store runs. Parts 2 and 3 are where we prove it.
WisWes builds AI that lives inside your store — answering shoppers, recommending products, and, soon, keeping your reviews honest. This series is us building one piece of that in the open.